效果图渲染
 影视动画渲染
影视动画渲染 CG MAGIC
CG MAGIC
效果图渲染平台
- 一键提交自动匹配软件插件,异常设置自动优化
- PC端、手机端双端监控,随时掌控进度
- 多种渲染模式自助选择,满足各种效率需求
- 海量福利活动,天天送不停
最新AI模型可生成高质量3D模型技术!
目前,说到AI生成3D模型,虽然效果上总有些差强人意,精度方面更是有待提高;但也得承认这项技术一直都在进步着,且每次步子都迈得挺大的。
本月,字节跳动就开始发大招了。字节跳动的研究团队最近推出了一款新的AI模型,能够通过文本提示生成高质量3D模型。
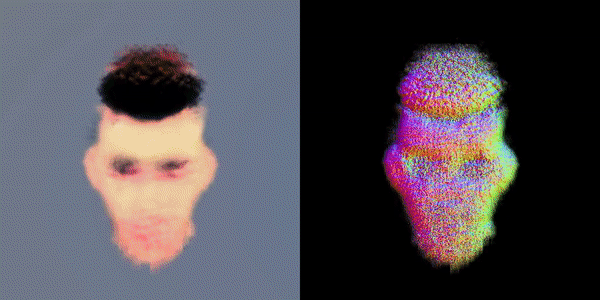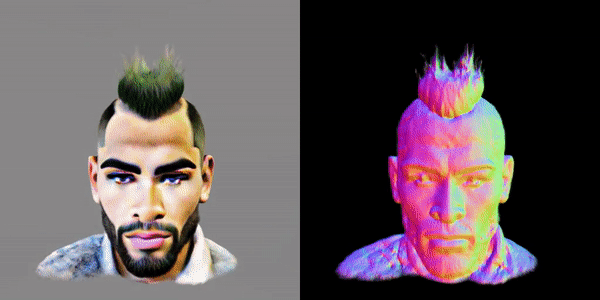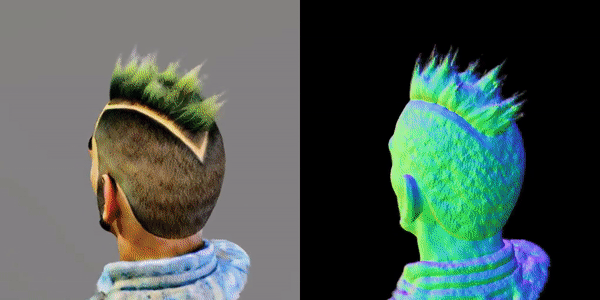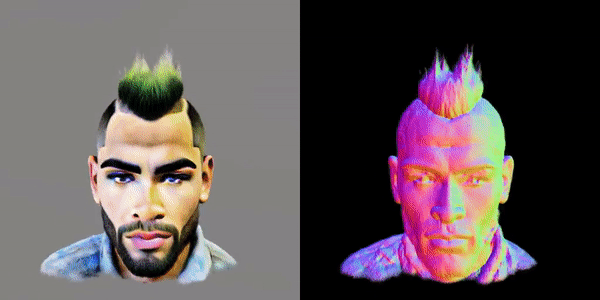
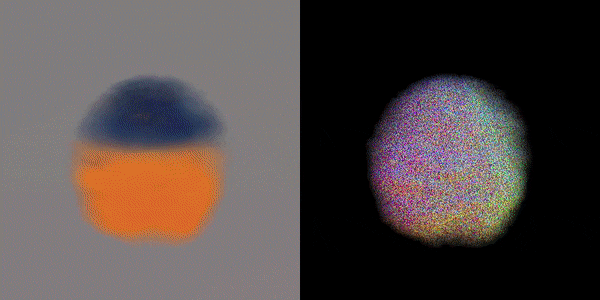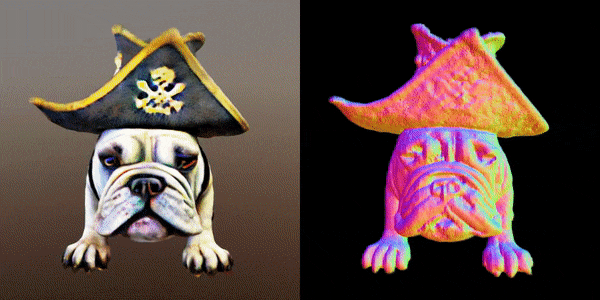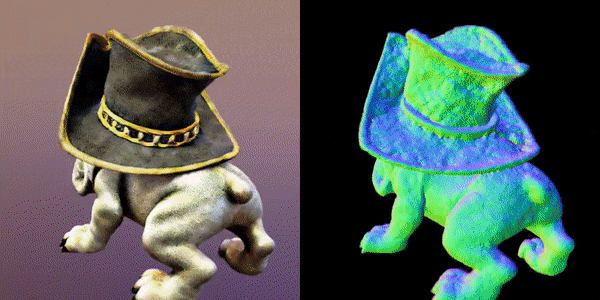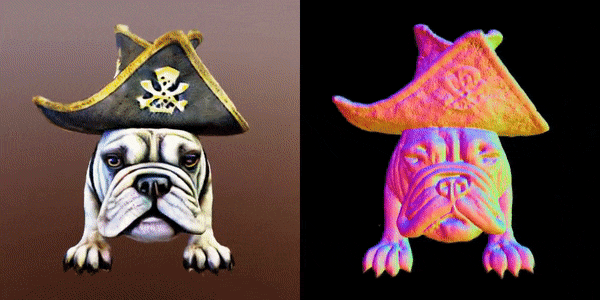
这款名为MVDream的多视角扩散模型,可以根据任意给定的文本提示生成物体/场景的多视角图像。
通过利用在大规模Web数据集和从3D资产中渲染的多视角数据集上预先训练的图像扩散模型,由此产生的多视角扩散模型同时结合了2D扩散模型的适应性和3D数据的一致性。
因此,该模型可以通过分数蒸馏采样为3D生成内容提供有价值的多视角参考,通过解决3D一致性问题极大地提高了现有2D提升方法的稳定性。
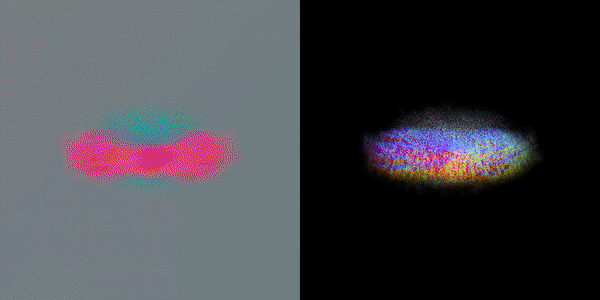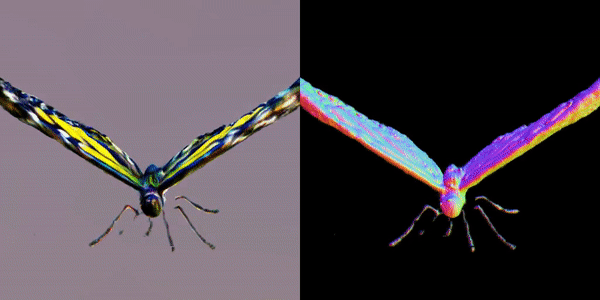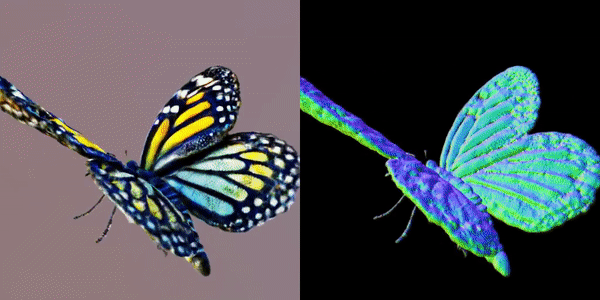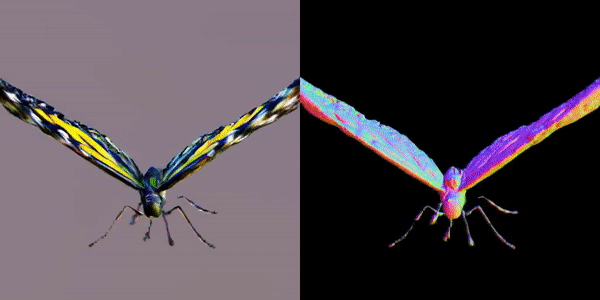
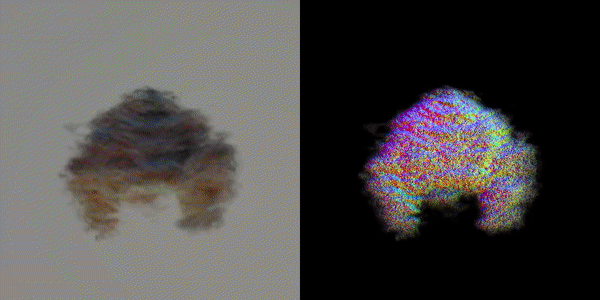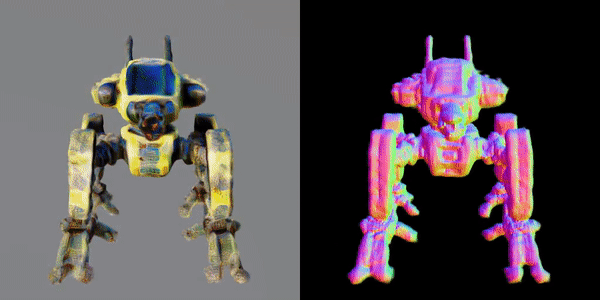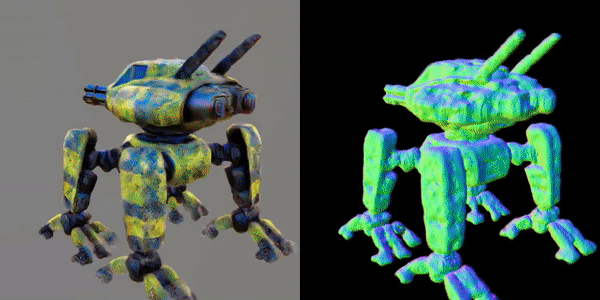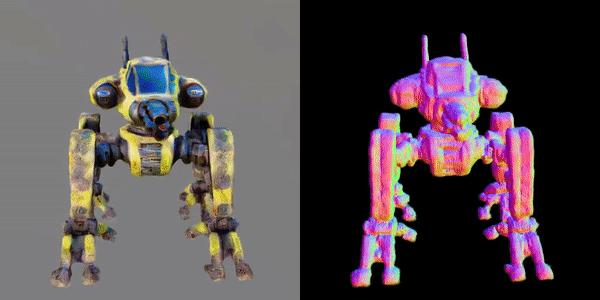
此外,该研究团队还指出,MVDream可以在极少样本的情况下进行微调,非常适合用于个性化的3D生成(如DreamBooth3D应用),在这种情况下,模型可以学习主体的特征,同时保持视角一致性。
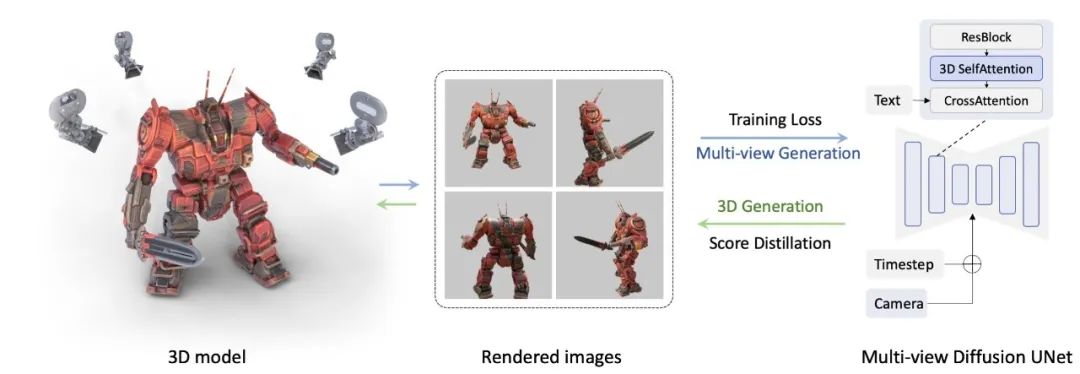
团队在关于MVDream的研究论文中写到:
通过在3D渲染数据和大规模文本到图像数据上预训练基础模型,我们的模型可以保持基础模型的通用性,同时实现多视角一致的生成。
通过全面的设计探索研究,我们发现使用带相机矩阵嵌入的3D自注意力机制就足以从训练数据中学习多视角一致性。结果表明,多视角扩散模型可以作为良好的3D先验模型,并且可以通过SDS应用于3D生成,这比当前的开源2D提升方法具有更好的稳定性和质量。最后,还可以在几个镜头设置下训练多视角扩散模型,以进行个性化3D生成。
渲云渲染行业头部公司,成立于2010年,品牌口碑好,服务好,专业TD团队为您项目保驾护航!支持效果图渲染、影视动画渲染,CR/VR,全类型软件插件支持,让您一键提交,轻松渲染。大幅提高工作效率,释放您的电脑。
渲云作为SAAS服务平台,其全面拥抱公有云的特性,使得海量节点可弹性拓展,算力按需取用,无论是建筑设计、室内家装、影视动画、工业设计、互动游戏、VR/AR等多领域三维内容制作,都能无缝衔接灵活、高效、快速的云端渲染服务。
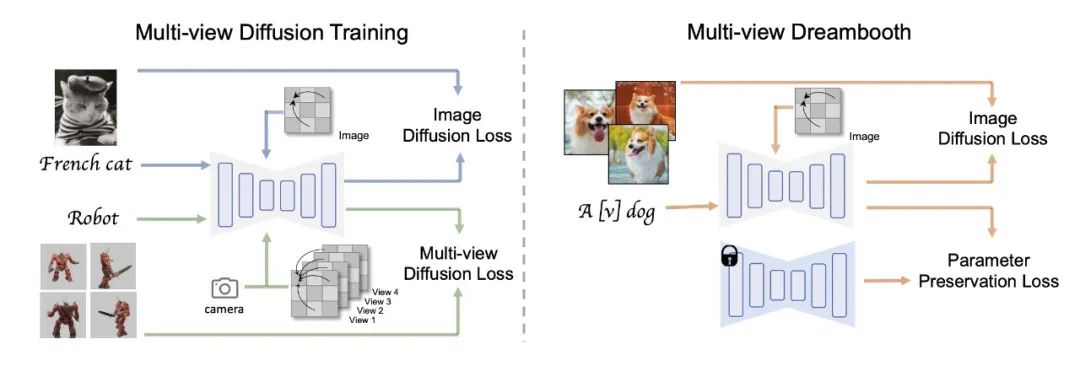
当然,MVDream目前还存在一定的局限性:
1)目前只能生成256×256分辨率的图像,这比原始Stable Diffusion的512×512要小,且当前模型的通用性似乎仅限于基础模型本身。研究团队期望通过增加数据集大小和使用更大的扩散模型替换基础模型来解决上述两个问题,例如SDXL(SDX)。
2)研究团队观察到MVDream生成的光照、纹理样式会和渲染数据集很相似。尽管可以通过添加更多样式文本提示来改善,但这也意味着需要更多样化和真实的渲染数据来训练出更好的多视角扩散模型,而这可能需要很高的计算成本。
最后,来看看官方给出与其他类似模型生成的结果对比:
团队收集了不同来源的多个文本提示,对所有提示均使用默认固定配置,没有使用threestudio软件进行超参数调整。(横向是同一个模型,每一列是不同的技术产生的结果,最右侧是字节跳动最新的技术结果)。


an astronaut riding a horse

baby yoda in the style of Mormookiee

Handpainted watercolor windmill, hand-painted

Darth Vader helmet, highly detailed
这么看的话,MVDream生成的模型显然质量不是高了一点点,要是真能达到这个效果。









